It’s a bit more than a decade since Mnih et al. (2015) combined deep learning with the classic reinforcement learning algorithm Q-learning to play Atari games straight from high-dimensional sensory inputs at human levels. This landmark paper sparked a wave of research in deep reinforcement learning that has led to significant advancements in various domains, including robotics, game playing, and natural language processing.
In this article, we will explore some of the most influential papers and ideas that have shaped the field of deep reinforcement learning over the past decade. Inspired by the blog post "The Decade of Deep Learning" from Leo Gao, we pick one article per year and explore the key ideas and contributions. We also include follow-up work that builds on top of the innovations. With this approach, we aim to give a concise overview of the key milestones of deep reinforcement learning that lets you start exploring deeper into this fascinating research field.
A little caution is necessary as the selection is by no means exhaustive and it’s incredibly hard to pinpoint and attribute individual ideas to a single author / paper. In addition, note that this article is a highly subjective selection of papers and ideas; year dates are approximated by the earliest publication date, mostly from arXiv.
2013: Deep Q-Network (DQN) ~61000 citations¶

Deep Q-Network (DQN) learning to play Atari games from raw pixel inputs. Cf. Mnih et al. (2015).
The story of modern deep reinforcement learning begins with Mnih et al. (2013) "Playing Atari with Deep Reinforcement Learning", later published in Nature as Mnih et al. (2015) "Human-level control through deep reinforcement learning". This groundbreaking work from DeepMind introduced the Deep Q-Network (DQN), the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning.
The core innovation of DQN lies in combining a convolutional neural network [LeCun et al., 2002] with Q-learning [Watkins & Dayan, 1992], a classic reinforcement learning algorithm. The network takes four stacked raw pixel inputs (84×84×4 grayscale images) and outputs action values (Q-values) for each possible action. Unstable training was a major challenge, so DQN introduced two key techniques to stabilize learning. First, experience replay stores experiences in a replay buffer and samples random mini-batches instead of learning from consecutive samples. This breaks correlations between consecutive observations and enables more efficient training. Second, a separate target network with periodically updated weights provides stable learning targets, preventing the "moving target" problem where the network chases its own rapidly changing predictions. The result was an agent that achieved human-level performance on many of the 49 Atari 2600 games tested, using the same architecture and hyperparameters across all games—demonstrating remarkable generality. More than a million training steps were required to achieve this performance though.
Many works have built on DQN’s foundation and improved individual components. For example, Double DQN [Hasselt et al., 2016] addressed the overestimation bias in Q-learning by decoupling action selection from action evaluation, using the online network to select actions but the target network to evaluate them. Prioritized Experience Replay [Schaul et al., 2015] replaced uniform sampling with sampling proportional to temporal-difference error, focusing learning on surprising or important experiences. Dueling DQN [Wang et al., 2015] separated the network into value and advantage streams, allowing the agent to learn which states are valuable without having to learn the effect of each action. Rainbow [Hessel et al., 2018] combined six such orthogonal improvements, detailing the contribution of each.
Agent57 [Badia et al., 2020] finally achieved superhuman performance on all 57 Atari games. Still based on the original DQN idea of learning a value function, Agent57 combined a meta-controller for exploration, a hybrid of intrinsic and extrinsic rewards, and a population of diverse agents to tackle the full suite of games.
2014: Deterministic Policy Gradient (DPG) ~6462 citations¶
While DQN excelled at discrete action spaces, many real-world problems—robotics, autonomous driving, continuous control—require continuous action spaces. Silver et al. (2014) "Deterministic Policy Gradient Algorithms" introduced the Deterministic Policy Gradient (DPG) at the ICML 2014, laying the theoretical foundation for continuous control with DRL.
The central insight of DPG is that for continuous actions, the policy gradient has a particularly elegant form. Unlike stochastic policy gradients that require integrating over both state and action spaces, the deterministic policy gradient only integrates over the state space:
Here denotes the policy parameters; is the performance objective (expected discounted return); is the deterministic policy mapping states to actions; is the (improper) discounted state distribution induced by the policy; is the gradient of the policy output with respect to ; is the action-value function under the policy; is the gradient of with respect to the action, evaluated at the action chosen by the policy in state .
This means the gradient can be estimated much more efficiently: the expectation is only over the state space (for each state, the policy gives a single action , so no integration or sampling over actions is needed), whereas the stochastic policy gradient [Sutton et al., 1999] requires integrating over both states and actions. In high-dimensional action spaces, that difference is decisive—sampling or approximating an integral over many action dimensions is costly, so the deterministic form scales far better. The paper also introduced an off-policy actor-critic algorithm: a behavior policy (e.g., the deterministic policy plus exploration noise) is used to collect experience and ensure adequate exploration, while the target policy (the deterministic policy being optimized) is updated from that experience. The gradient can then be estimated from off-policy data so that learning remains sample-efficient.
DPG became the foundation for several influential algorithms. DDPG [Lillicrap et al., 2016], which we will discuss in more detail in the next section. TD3 (Twin Delayed DDPG) [Fujimoto et al., 2018] addressed overestimation in actor-critic methods using twin critics, delayed policy updates, and target policy smoothing. SAC [Haarnoja et al., 2018] added entropy regularization for better exploration and robustness; we will also take a closer look at this algorithm later.
2015: Deep Deterministic Policy Gradient (DDPG) ~21875 citations¶
Lillicrap et al. (2016) (arXiv 2015, ICLR 2016) introduced Deep Deterministic Policy Gradient (DDPG), adapting the success of DQN to continuous action domains. This was the first DRL algorithm to robustly solve a wide range of continuous control problems.

DDPG ablation runs on a continuous control task: original DPG algorithm with batch normalization (light grey), with target network (dark grey), with target networks and batch normalization (green), with target networks from pixel-only inputs (blue). Cf. Lillicrap et al. (2016).
DDPG is an actor-critic algorithm that learns both a policy (actor) and a Q-function (critic). The actor-critic architecture has the actor network output continuous actions directly, while the critic evaluates state-action pairs. Instead of periodically copying weights, DDPG uses soft target updates () for smoother learning. Batch normalization normalizes inputs across the network to handle different physical units and scales, while Ornstein-Uhlenbeck noise provides temporally correlated exploration for physical control tasks.
Using the same algorithm, architecture, and hyperparameters, DDPG solved over 20 simulated physics tasks including cartpole swing-up, dexterous manipulation, and legged locomotion—some directly from pixel inputs.
2016: AlphaGo ~23814 citations¶
Silver et al. (2016) "Mastering the Game of Go with Deep Neural Networks and Tree Search" achieved what many considered a decade away: defeating a professional human player at Go. AlphaGo combined deep neural networks with Monte Carlo tree search (MCTS) in a revolutionary approach that has reshaped our understanding of game-playing AI.
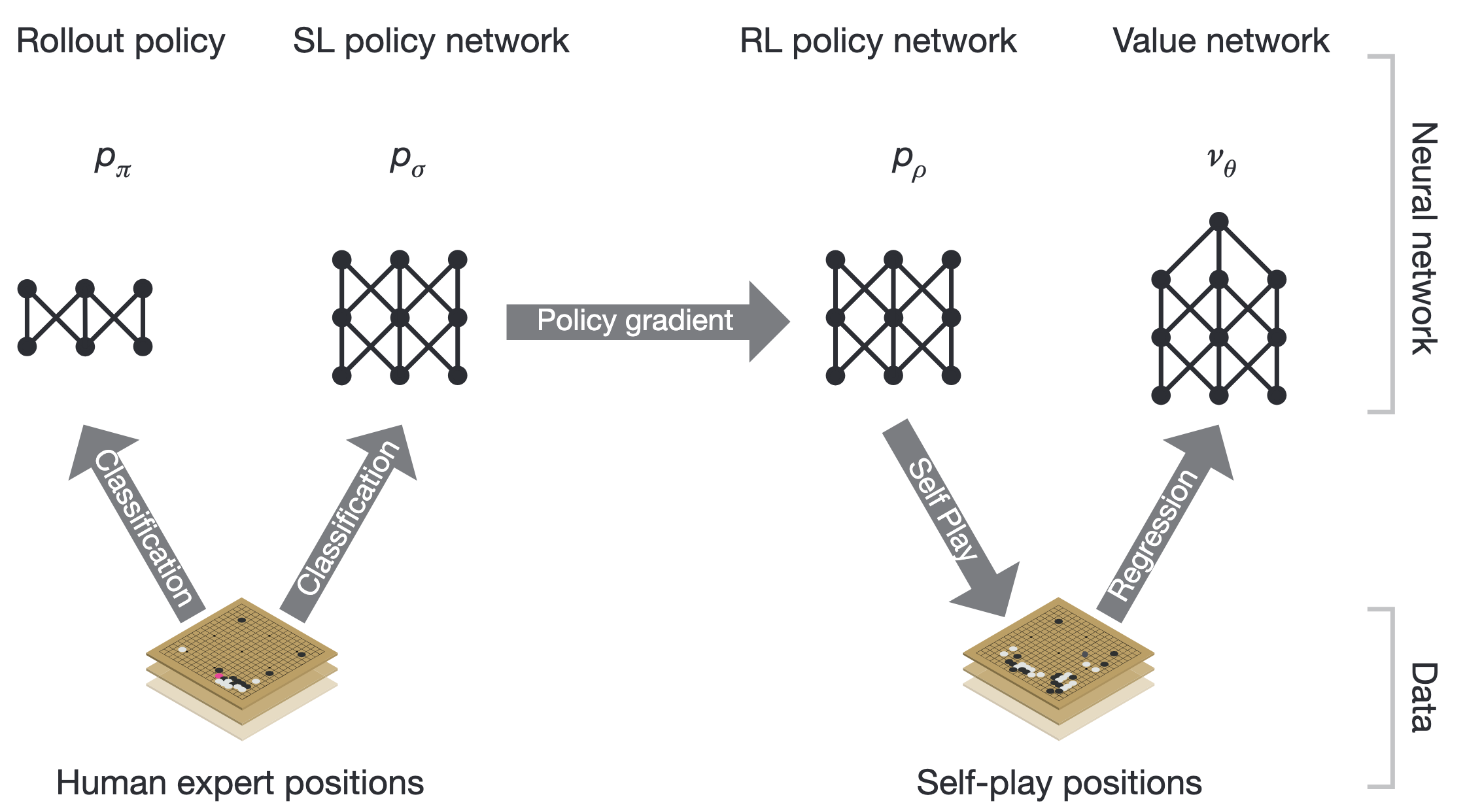
AlphaGo training pipeline starting with supervised learning on expert games and then reinforcement learning from self-play. Cf. Silver et al. (2016).
AlphaGo introduced a novel combination of techniques. A policy network—a deep CNN trained via supervised learning on expert human games—predicts move probabilities and guides the Monte Carlo tree search (MCTS) [Kocsis & Szepesvári, 2006] toward promising moves. A separate value network predicts game outcomes from board positions, enabling position evaluation without playing to the end. The policy network was further improved through reinforcement learning from self-play, playing millions of games against itself.
AlphaGo defeated Lee Sedol, one of the world’s strongest players, 4-1 in a historic match that demonstrated the power of DRL beyond video games.
The AlphaGo lineage continued with increasingly general algorithms. AlphaGo Zero [Silver et al., 2017] learned entirely from self-play without prior human knowledge, discovering novel strategies that surprised even professional players. AlphaZero [Silver et al., 2018] generalized to chess and shogi with the same algorithm, defeating world champion programs in all three games within hours of training. MuZero [Schrittwieser et al., 2020] took this further by learning a world model without explicit game rules, achieving superhuman performance on Go, chess, shogi, and Atari games—elegantly bridging model-free and model-based RL.
2017: Proximal Policy Optimization (PPO) ~12113 citations¶
Schulman et al. (2017) "Proximal Policy Optimization Algorithms" introduced Proximal Policy Optimization (PPO) at NIPS 2017, which has become a default algorithm for many RL applications due to its simplicity, stability, and strong performance.
PPO builds on Trust Region Policy Optimization (TRPO) [Schulman et al., 2015], which guaranteed monotonic improvement but was computationally complex. PPO achieves similar benefits with a simpler clipped surrogate objective :
where denotes the policy parameters; is the probability ratio between new and old policies; is the advantage estimator at ; is clipped to ; is the clipping hyperparameter.
The key insight is to clip the probability ratio, preventing excessively large policy updates that could destabilize learning. This removes the need for complex second-order optimization while maintaining stable learning.
PPO’s success stems from several factors. Its simplicity—using only first-order optimization—makes it easy to implement and tune. The clipping mechanism provides stability by preventing catastrophic policy updates. Sample efficiency is improved because the same batch of data can be used for multiple epochs of updates. Finally, its generality allows it to work across discrete and continuous actions in diverse domains.
PPO became the algorithm of choice for training large language models via Reinforcement Learning from Human Feedback (RLHF), which we cover later, OpenAI Five (Dota 2), and countless robotics applications.
2018: Soft Actor-Critic (SAC) ~11040 citations¶
Haarnoja et al. (2018) "Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor" introduced Soft Actor-Critic (SAC) at ICML 2018, an off-policy algorithm based on maximum entropy reinforcement learning that achieves state-of-the-art sample efficiency with remarkable stability.
SAC’s central idea is to augment the standard RL objective with an entropy term, encouraging the agent to act as randomly as possible while still succeeding at the task. The objective measures how good a policy is by summing, over all timesteps , the expected reward plus the entropy of the policy at state , where the expectation is taken over state-action pairs sampled from the trajectory distribution induced by . A temperature parameter controls the relative importance of entropy versus reward:
This maximum entropy formulation provides several benefits. The entropy bonus encourages exploration by rewarding diverse actions. The stochastic policy provides robustness, handling uncertainty and multimodal action distributions gracefully. Learning stability is improved by preventing premature convergence to deterministic policies. Additionally, automatic temperature tuning adjusts the entropy coefficient dynamically during training.
SAC combines the sample efficiency of off-policy methods with the stability of entropy regularization, making it the go-to algorithm for continuous control and robotics.
Also worth mentioning is Fujimoto et al. (2018), who introduced TD3 (Twin Delayed DDPG). TD3 identified that function approximation error in actor-critic methods leads to overestimated value estimates and suboptimal policies, and addressed this with three techniques: clipped double Q-learning (taking the minimum of two independent critics), delayed policy updates (updating the actor less frequently than the critic), and target policy smoothing (adding noise to target actions as a regularizer). These simple modifications to DDPG yielded significant improvements on continuous control benchmarks.
2019: Dreamer ~1656 citations¶
Hafner et al. (2020) "Dream to Control: Learning Behaviors by Latent Imagination" introduced Dreamer at ICLR 2020, a model-based RL agent that learns behaviors entirely through imagination. Building on PlaNet [Hafner et al., 2019], Dreamer represents a major step toward sample-efficient RL.
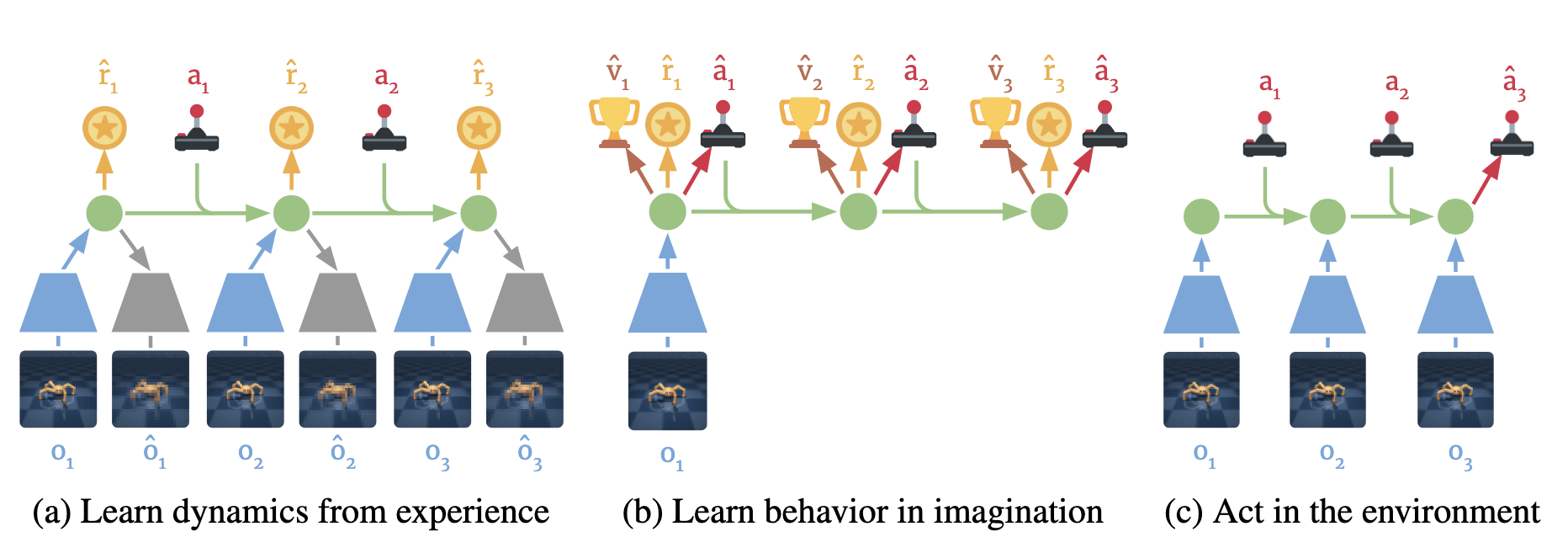
Components of Dreamer. (a) From the dataset of past experience, the agent learns to encode observations and actions into compact latent states and predicts environment rewards. (b) In the compact latent space, Dreamer predicts state values and actions that maximize future value predictions by propagating gradients back through imagined trajectories. (c) The agent encodes the history of the episode to compute the current model state and predict the next action to execute in the environment. Cf. Hafner et al. (2020).
Dreamer learns a world model and uses it to imagine future trajectories in latent space. At its core is the Recurrent State-Space Model (RSSM), a latent dynamics model combining deterministic and stochastic components to capture both predictable dynamics and environmental uncertainty. The key insight is learning in imagination: instead of interacting with the environment, the agent imagines trajectories using the learned model and learns from these imagined experiences. Policies and value functions operate entirely in the compact latent space through an actor-critic in latent space architecture, enabling efficient backpropagation through imagined trajectories. Unlike model-free methods that estimate gradients through sampling, Dreamer uses analytic gradients, backpropagating directly through the world model [Ha & Schmidhuber, 2018].
Dreamer achieved state-of-the-art performance on 20 challenging visual control tasks with significantly fewer environment interactions. The Dreamer line continued to evolve. DreamerV2 introduced discrete latent representations, significantly improving learning stability. DreamerV3 [Hafner et al., 2023] achieved a remarkable milestone: a single algorithm that outperforms specialized methods across more than 150 diverse tasks with no hyperparameter tuning. Notably, it was the first algorithm to collect diamonds in Minecraft from scratch without human data—a long-standing challenge in the field.
2020: Contrastive Unsupervised Representations for Reinforcement Learning (CURL) ~1140 citations¶
Srinivas et al. (2020) "Contrastive Unsupervised Representations for Reinforcement Learning" introduced CURL at ICLR 2020, bringing the revolution of self-supervised learning to reinforcement learning.
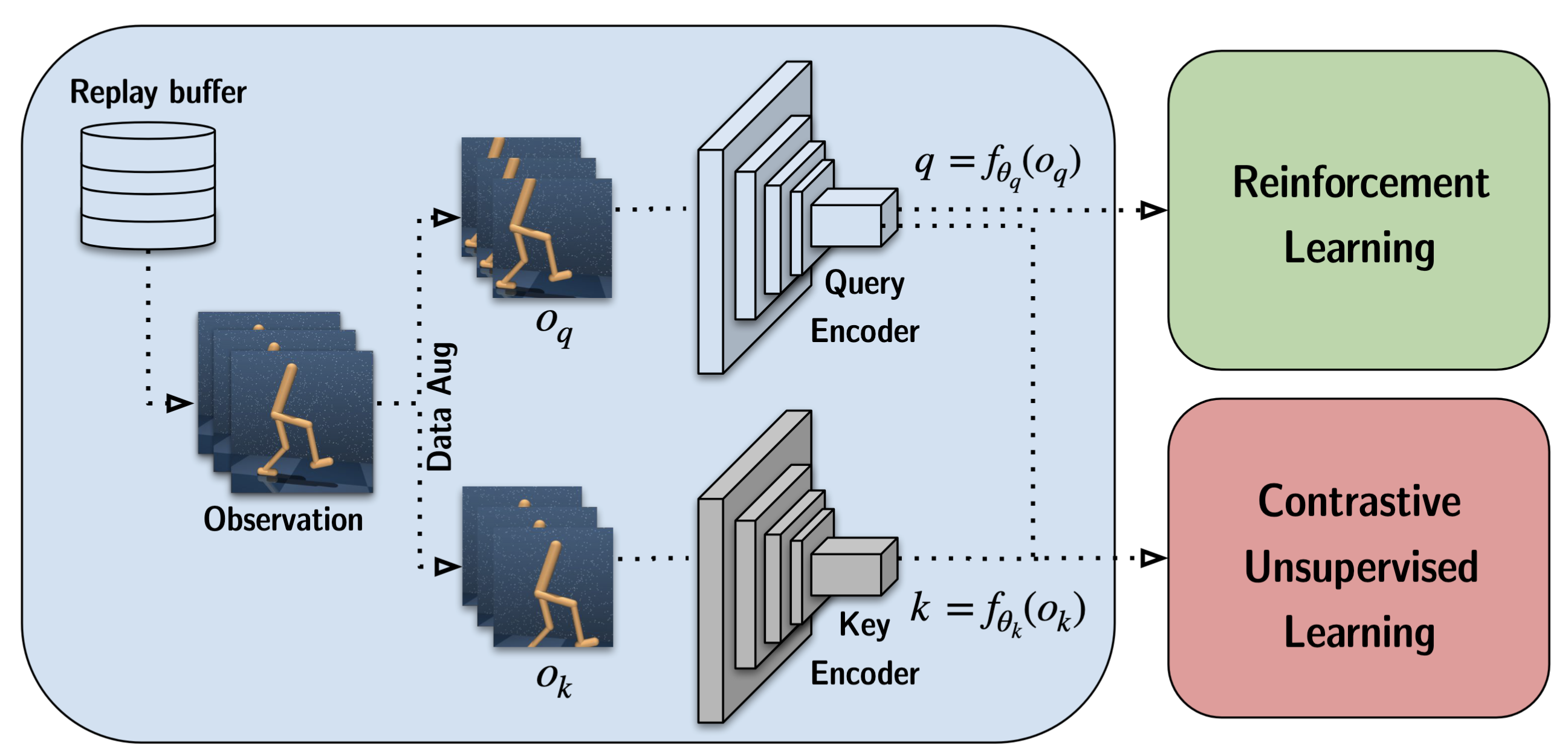
CURL architecture: observations from the replay buffer are augmented to produce query () and key () views, encoded by separate networks into representations and . The query representation feeds the RL policy and value learning; both and are used in the contrastive unsupervised objective. Cf. Srinivas et al. (2020).
CURL applies contrastive learning to learn visual representations alongside the RL objective. Through instance discrimination, CURL uses data augmentation (random crops) to create positive pairs and treats other samples as negatives, learning representations that capture task-relevant features. The contrastive loss serves as an auxiliary objective added alongside the standard RL loss, improving representation quality without requiring reconstruction. The result was dramatically improved sample efficiency: CURL achieved near state-based performance on DeepMind Control Suite, effectively closing the gap between pixel-based and state-based RL.
Around the same time, SPR (Self-Predictive Representations) [Schwarzer et al., 2021] (arXiv 2020) took a complementary approach to self-supervised representation learning in RL. Instead of contrastive learning, SPR trains the encoder to predict its own future latent representations. Given a current observation, the agent predicts the latent states several steps into the future using a learned transition model, and the loss encourages these predictions to match the representations produced by a momentum encoder (à la BYOL). Combined with data augmentation and a Rainbow-based RL backbone, SPR achieved state-of-the-art performance in the Atari 100k benchmark—a challenging low-data regime where agents are limited to just 100k environment steps (roughly two hours of human play).
Together, CURL and SPR demonstrated that modern self-supervised learning techniques could dramatically improve the sample efficiency of DRL, whether through contrastive objectives or predictive latent dynamics. This line of work continued with important follow-ups. The Primacy Bias [Nikishin et al., 2022] identified a fundamental obstacle to sample efficiency: DRL agents overfit to early training data, and this bias persists even as new data arrives. A simple remedy—periodically resetting parts of the network—dramatically improved performance and combined naturally with representation learning methods like SPR. Building on these insights, BBF (Bigger, Better, Faster) [Schwarzer et al., 2023] scaled up the SPR recipe with larger networks, higher replay ratios, and carefully tuned resets to achieve human-level performance on the Atari 100k benchmark with human-level data efficiency—a first for the field.
2020 was also a landmark year for offline reinforcement learning, with methods that learn entirely from fixed datasets without environment interaction. Key works include Conservative Q-Learning [Kumar et al., 2020], MOReL [Kidambi et al., 2020], and the D4RL benchmark [Fu et al., 2020].
2021: Decision Transformer ~2604 citations¶
Chen et al. (2021) reimagined reinforcement learning as sequence modeling, bridging RL with the transformer revolution in NLP and computer vision.
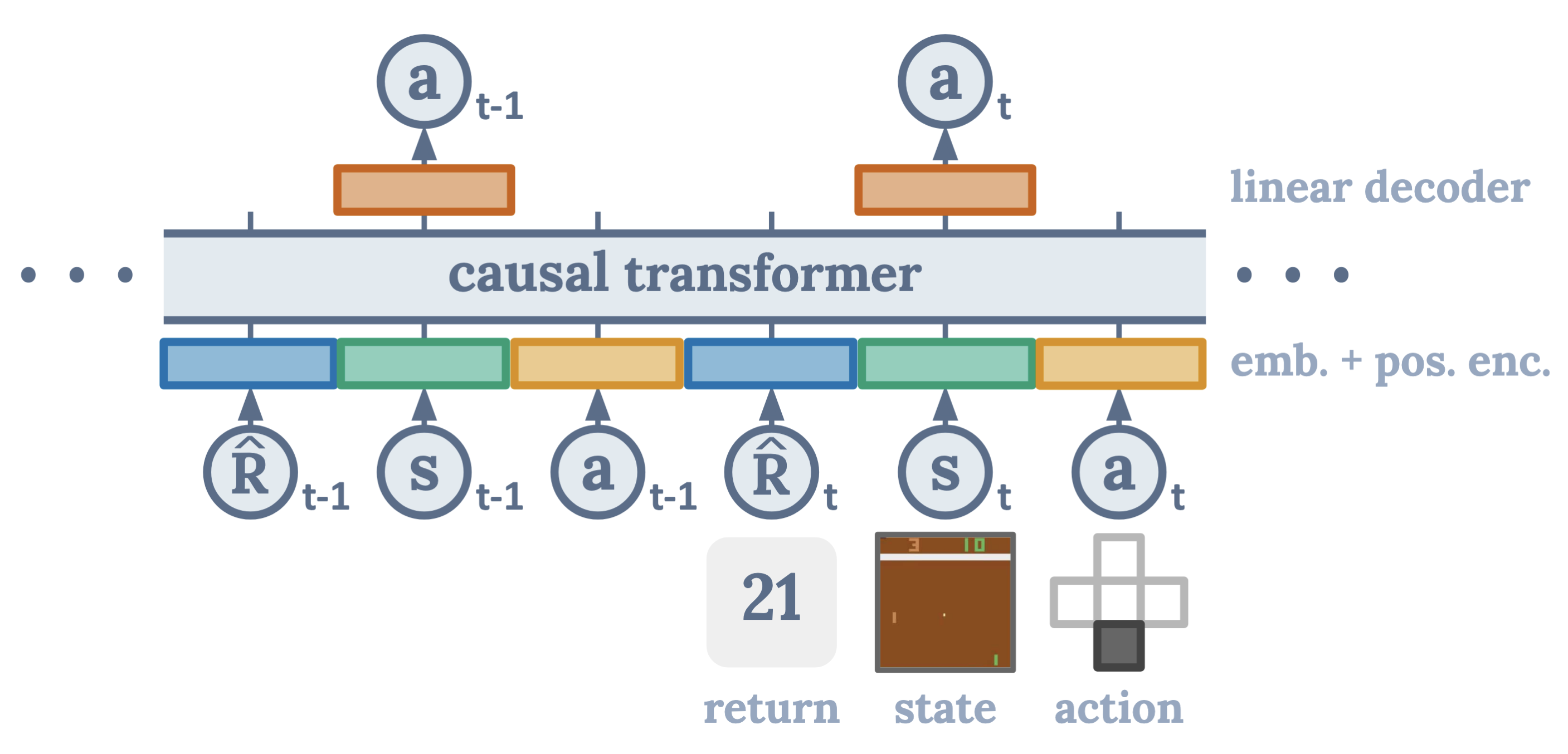
Decision Transformer: a causal transformer conditioned on desired return , states , and actions ; it predicts actions via a linear decoder. Cf. Chen et al. (2021).
Decision Transformer reframes RL as predicting actions conditioned on desired outcomes. Through return conditioning, the model is conditioned on the desired return-to-go, allowing it to generate actions that achieve specified performance levels. Trajectories are treated as sequences of (return, state, action) tokens in a sequence modeling framework, enabling the use of transformer architectures. Unlike traditional RL that bootstraps value estimates, Decision Transformer requires no Bellman backups, instead using supervised learning on trajectories. The architecture is a GPT-style causal transformer [Radford et al., 2018] that predicts actions given the history of states, actions, and target returns.
Despite its simplicity, Decision Transformer matched or exceeded the performance of state-of-the-art offline RL algorithms on Atari and continuous control benchmarks.
Decision Transformer opened a new paradigm for RL, inspiring numerous follow-up works. Trajectory Transformer [Janner et al., 2021] extended the idea by using beam search for planning in transformer-modeled trajectories. Gato [Reed et al., 2022] from DeepMind demonstrated a generalist agent using transformers across hundreds of diverse tasks. More broadly, the work sparked interest in foundation models for decision-making [Yang et al., 2023] that leverage pretrained transformers, connecting RL with the broader trend of large-scale pretraining.
2022: Reinforcement Learning from Human Feedback (RLHF) ~23131 citations¶
Ouyang et al. (2022) "Training Language Models to Follow Instructions with Human Feedback" introduced InstructGPT at NeurIPS 2022, demonstrating how Reinforcement Learning from Human Feedback (RLHF) can align large language models with human intent—a technique that has become central to modern AI assistants.
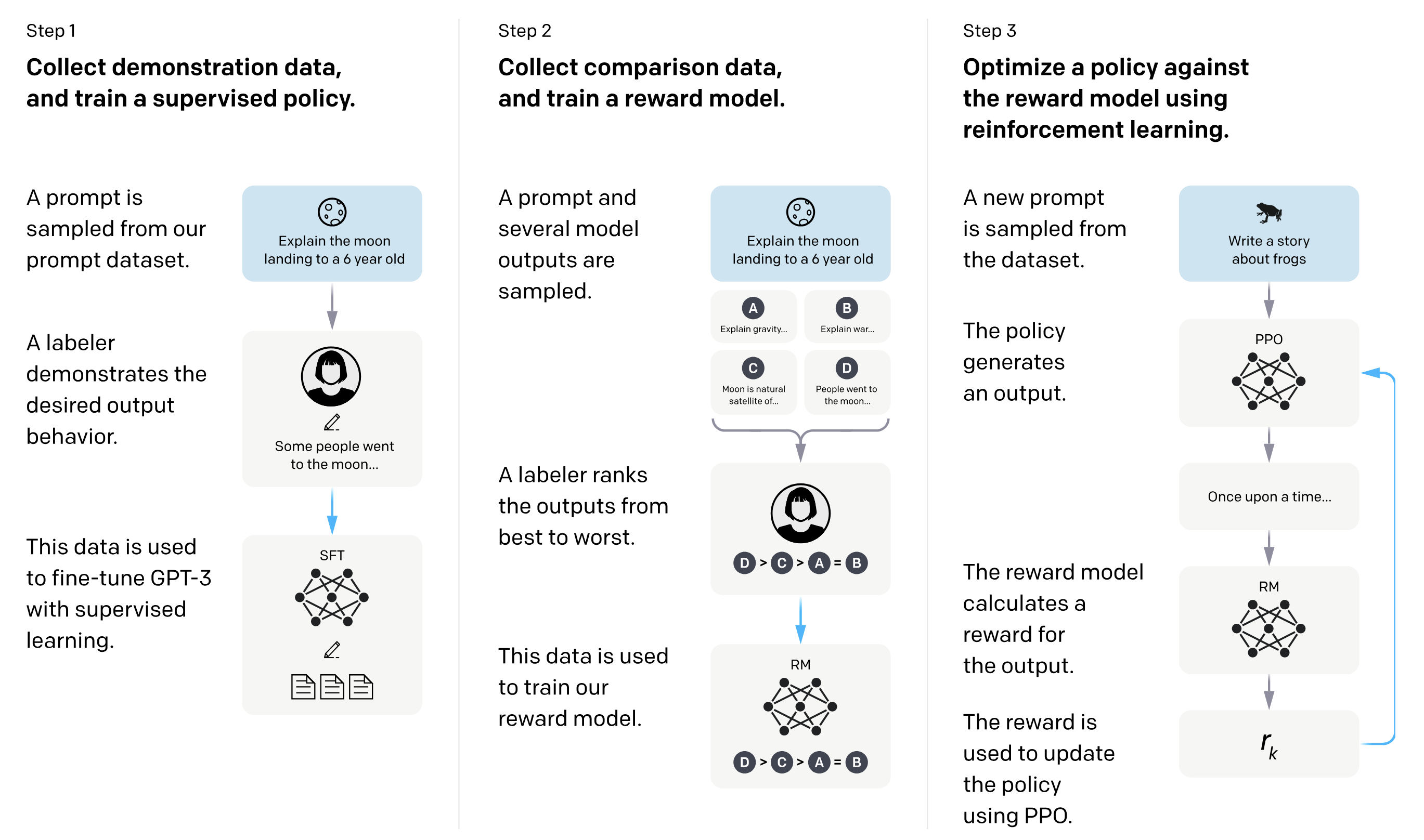
InstructGPT training pipeline: (1) Collect demonstration data and train a supervised policy (SFT). (2) Collect comparison data and train a reward model (RM) from human rankings. (3) Optimize the policy against the reward model using PPO. Cf. Ouyang et al. (2022).
InstructGPT aligns language models with human preferences through a three-stage process. First, supervised fine-tuning trains the model on human-written demonstrations of desired behavior. Then, reward modeling collects human rankings of model outputs and trains a reward model to predict human preferences. Finally, RL fine-tuning uses PPO to optimize the language model against the learned reward while staying close to the supervised policy via a KL penalty. Remarkably, the 1.3B parameter InstructGPT model was preferred by human evaluators over the 175B parameter GPT-3, despite being over 100x smaller—demonstrating that alignment training can be more impactful than simply scaling model size.
This work, alongside Bai et al. (2022) from Anthropic who further explored training both helpful and harmless assistants with RLHF, established RLHF as the standard approach for aligning large language models, enabling the creation of ChatGPT, Claude, and other AI assistants.
2023: Temporal-Difference Model Predictive Control 2 (TD-MPC2) ~357 citations¶
Hansen et al. (2024) presented TD-MPC2, a model-based reinforcement learning algorithm that performs temporal-difference model predictive control in the latent space of a learned world model. Unlike reconstruction-based world models, TD-MPC2 uses a decoder-free (implicit) world model, reducing reliance on pixel reconstruction and improving robustness.
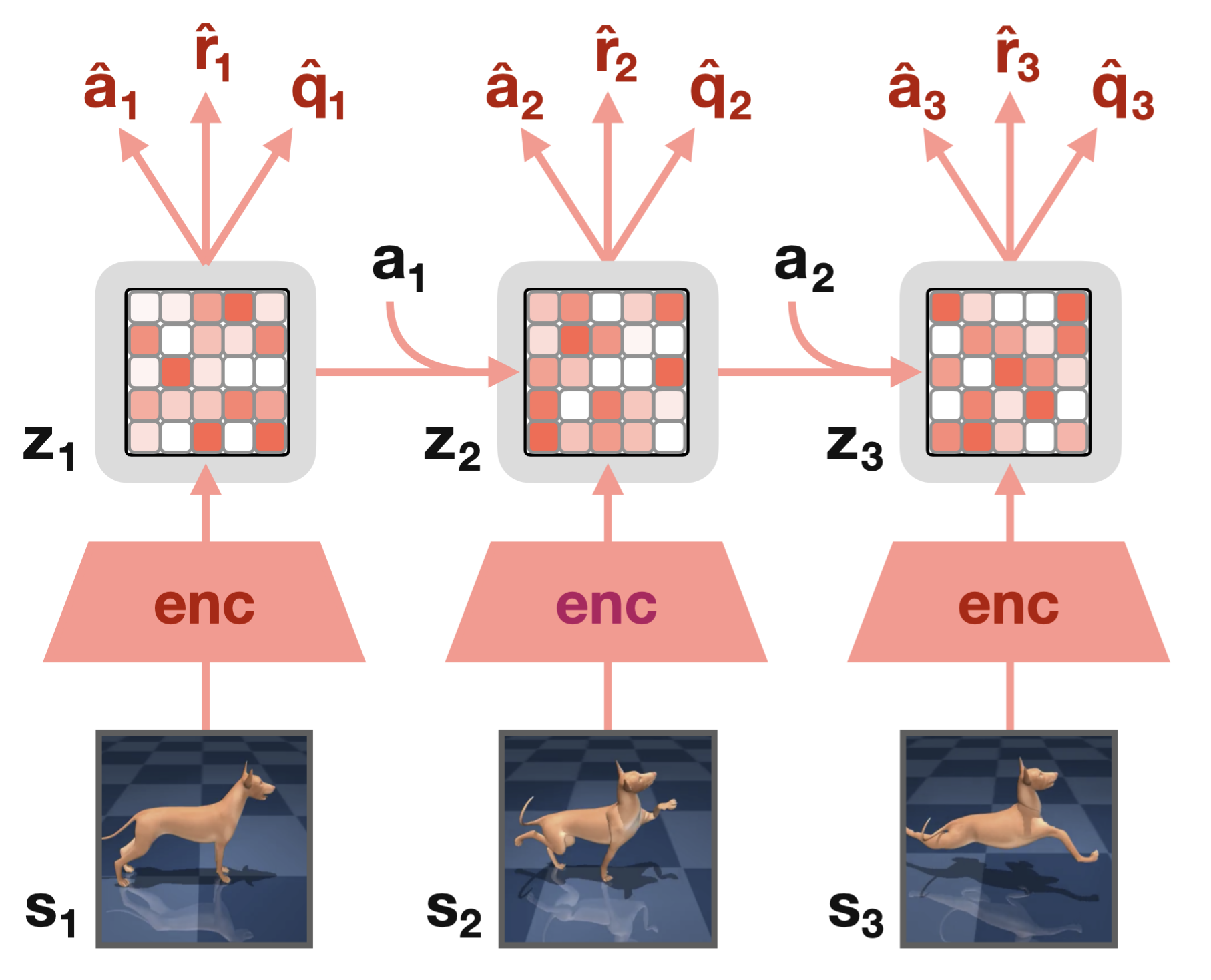
TD-MPC2 recurrent architecture: observations are encoded into latent states ; actions drive transitions in latent space; from each the model predicts action , reward , and Q-value . Cf. Hansen et al. (2024)
TD-MPC2 achieves strong performance across 104 online RL tasks spanning four domains—DMControl, Meta-World, ManiSkill2, and MyoSuite—with a single set of hyperparameters. The method compares favorably to both model-free baselines such as SAC and model-based alternatives including DreamerV3 and TD-MPC. The authors demonstrated scalability: agent capability improves with model and data size, and they trained a single 317M parameter agent to perform 80 tasks across multiple domains, embodiments, and action spaces. They released hundreds of model checkpoints and large transition datasets to support further research.
2024: AlphaProof ~41 citations¶
Google DeepMind (2025) introduced AlphaProof, an AlphaZero-inspired reinforcement learning system for formal theorem proving in Lean [Moura & Ullrich, 2021]. Rather than optimizing for benchmark game scores, AlphaProof optimizes the search process for machine-checkable mathematical proofs, pushing RL into one of the most difficult reasoning domains.
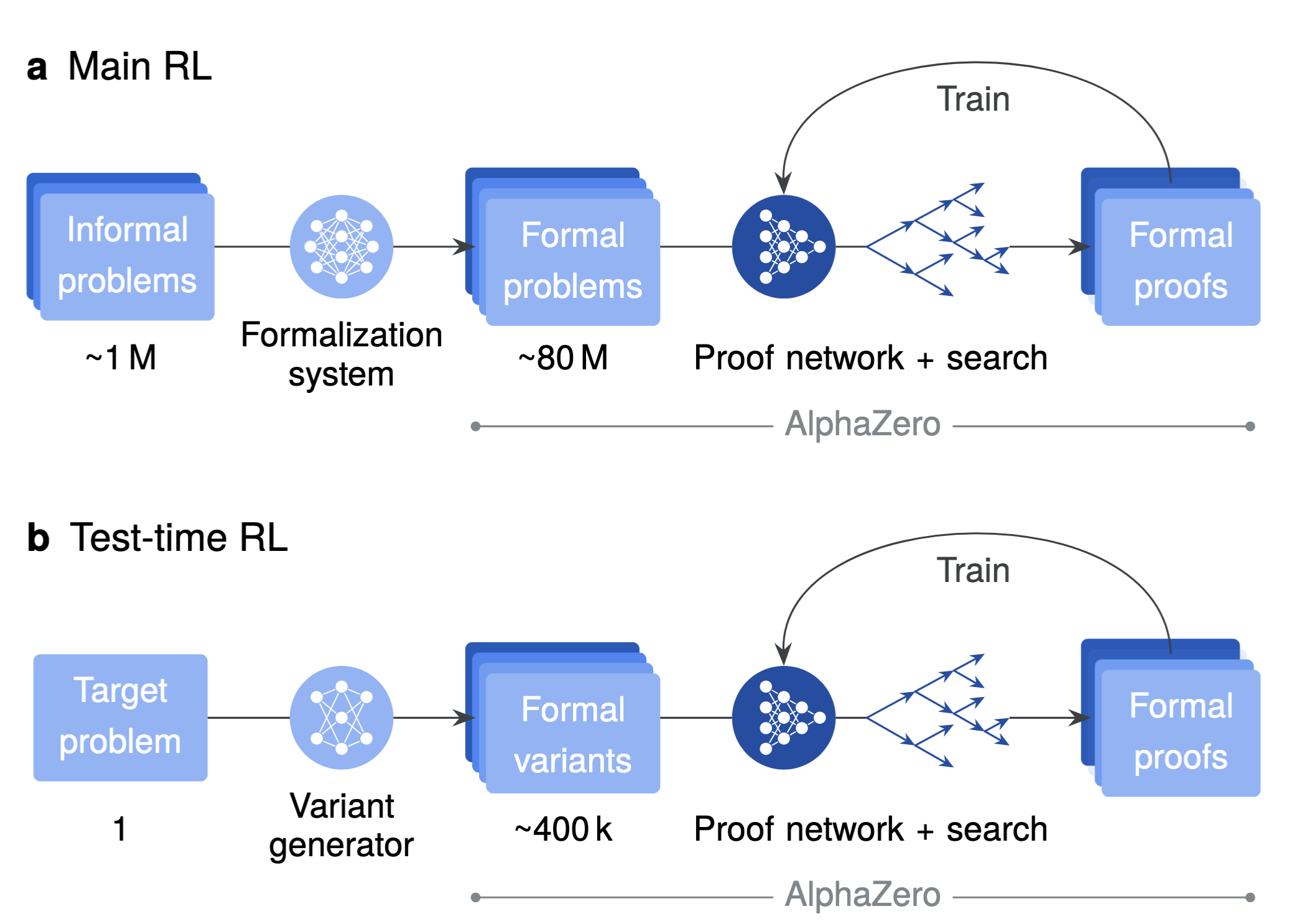
AlphaProof training and adaptation pipeline: (a) main RL over a large auto-formalized corpus, and (b) test-time RL on generated variants of a target problem. Cf. Google DeepMind (2025).
AlphaProof casts proving as a sequential decision process in a verifiable environment: each state is a Lean tactic state (goals + hypotheses), each action is a generated tactic, and rewards favor shorter proofs. Its core proof network is a 3B-parameter encoder-decoder transformer that predicts both a policy (which tactics to try) and a value (expected proof difficulty). These predictions guide a specialized tree search with adaptations for theorem proving, including handling multi-goal decomposition (AND-OR structure) and progressive tactic sampling to explore diverse proof paths. Critically, every successful output is checked by Lean’s kernel, giving correctness guarantees unavailable in purely natural-language reasoning systems.
The training recipe is also central to the result. AlphaProof starts from broad pretraining and supervised fine-tuning on formal proofs, then scales a main RL loop on a massive curriculum built by auto-formalizing roughly 1 million informal problems into about 80 million formal problems. For hard targets, the system uses Test-Time RL (TTRL) [Zuo et al., 2025]: it generates hundreds of thousands of related formal variants and runs focused RL adaptation at inference time. On held-out formal math benchmarks (including historical IMO-style and Putnam-style sets), this combination of large-scale RL and inference-time adaptation set a new state of the art. At IMO 2024, AlphaProof solved 3 of 5 non-geometry problems (including the hardest problem, P6); combined with a dedicated geometry system, the overall pipeline reached 28/42 points, equivalent to silver-medal performance.
2025: DeepSeek-R1 ~383 citations¶
DeepSeek AI (2025) DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning, published in Nature (2025), marks a major expansion of deep reinforcement learning from control and game-playing into long-horizon language reasoning. The central contribution is empirical: starting from a pretrained base model, pure RL with verifier-backed rewards (correctness and output format) can produce strong chain-of-thought reasoning without supervised reasoning traces. In DeepSeek-R1-Zero, this leads to emergent behaviours—self-verification, reflection, and strategy revision—that improve performance on verifiable domains such as mathematics and coding.
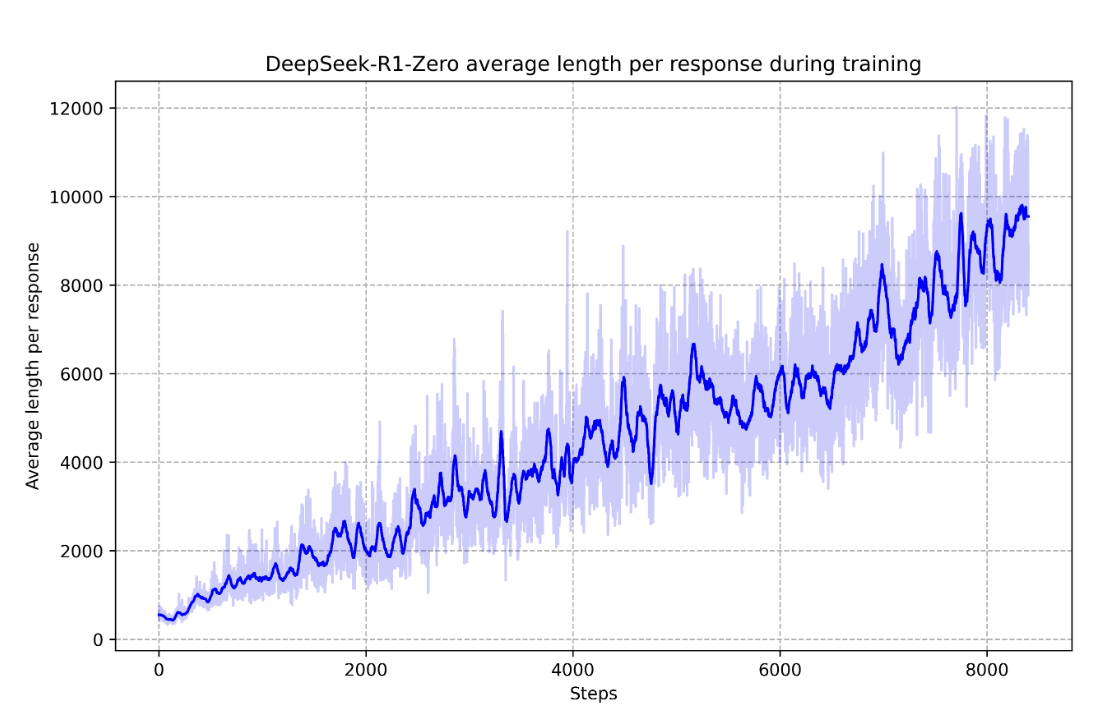
DeepSeek-R1-Zero average response length during RL training (adapted from Fig. 1b in DeepSeek AI (2025)). The steady growth in tokens reflects increasing test-time computation and richer internal deliberation as training progresses.
From a DRL perspective, the paper contributes a practical recipe for scaling policy optimization in language environments where rewards are programmatically verifiable: Group Relative Policy Optimization (GRPO; Shao et al., 2024), group-relative advantage estimation, and large-scale rollout training with long trajectories. It also clarifies a key design lesson for DRL in LLMs: unrestricted pure RL can unlock reasoning, but a multistage pipeline (cold-start data, SFT, additional RL with helpfulness/harmlessness rewards) is needed to recover readability, alignment, and broad assistant quality. Finally, by releasing distilled smaller models that inherit reasoning gains, the work suggests that RL-discovered reasoning behaviours can be transferred efficiently, making advanced reasoning more accessible.
Beyond research benchmarks, DeepSeek-R1 was widely reported to have had visible market impact: its release was associated with sharp repricing in AI-related equities as investors reassessed the cost-performance frontier for reasoning models and the competitive landscape for model providers and hardware vendors. Such an immediate stock-market reaction is uncommon for RL research papers, which typically influence the field through gradual technical adoption rather than near-term financial signals.
Conclusion¶
Over the past decade, deep reinforcement learning has evolved from playing Atari games to training the AI assistants we use daily. Key themes emerge from this journey.
The field progressed from discrete to continuous control: early work focused on discrete actions with DQN, but continuous control quickly followed with DDPG and SAC. Stability and sample efficiency improved dramatically through techniques like experience replay, target networks, and entropy regularization. Model-based learning through world models like Dreamer enabled learning through imagination, dramatically improving sample efficiency. Representation learning via self-supervised methods like CURL brought the power of modern representation learning to RL. Sequence modeling through transformers, as in Decision Transformer, offered a new paradigm connecting RL with foundation models. Finally, human alignment through RLHF has become essential for aligning AI systems with human values.
The field continues to evolve rapidly, with world models, offline RL, and reasoning agents representing exciting frontiers. We look forward to the next decade of discoveries.