From DQN to REINFORCE in 39 Iterations¶
Letting an AI agent optimize an RL algorithm on CartPole-v1 using the autoresearch loop.
The Idea¶
I recently checked out the TorchRL Introduction, while the library sounds amazing, I was a bit disappointed to not get an agent solving the simple environment. After tweaking the algorithm by myself a bit, I wondered what happens when you give an AI coding agent the script and tell it to make it better --- autonomously, with no human in the loop?
That is the premise behind autoresearch, a pattern introduced by Andrej Karpathy in March 2026 [Karpathy, 2026]. The core loop is deceptively simple: modify the code, run verification, keep if improved, discard if not, repeat. Karpathy demonstrated this on LLM training, running 700 experiments in two days and discovering 20 optimizations that transferred to larger models.
We applied this pattern --- via the Claude Code autoresearch skill by Udit Goenka [Goenka, 2026] --- to a different domain: optimizing a Deep Q-Network (DQN) [Mnih et al., 2013] agent on the classic CartPole-v1 benchmark. The agent started with a baseline scoring 207.6 average reward and, after 39 iterations, arrived at a REINFORCE [Williams, 1992] implementation achieving a perfect score of 500 in under 10 seconds --- a 43 reduction in required training frames.
The Setup¶
The rules were straightforward:
Goal: achieve a perfect score of 500 on CartPole-v1, consistently
Constraint: training + evaluation must complete in under 5 minutes on a M1 Macbook
Metric: average reward over 5 evaluation episodes (higher is better)
Scope: a single Python file (
algorithm.py)
The autoresearch loop works as follows:
LOOP:
1. Review current state + git history + results log
2. Pick ONE focused change
3. Make the change, git commit
4. Run verification (python algorithm.py)
5. If metric improved → keep. If worse → git revert.
6. Log the result to autoresearch-results.tsv
7. Repeat.Every experiment is committed before verification, so git revert provides clean rollback. Failed experiments stay visible in the git history --- they are the agent’s memory of what not to try again.
Phase 1: Optimizing DQN (Iterations 0--22)¶
The initial implementation used TorchRL [Bou et al., 2024] with a standard DQN setup: two-layer network (128 hidden units), -greedy exploration, replay buffer of 50,000 transitions, soft target updates (), and Adam optimizer at .
Baseline result: METRIC = 207.6. The agent would briefly spike to 400 reward around step 241k, then catastrophically collapse back to 9.
The first 22 iterations explored the DQN hyperparameter space:
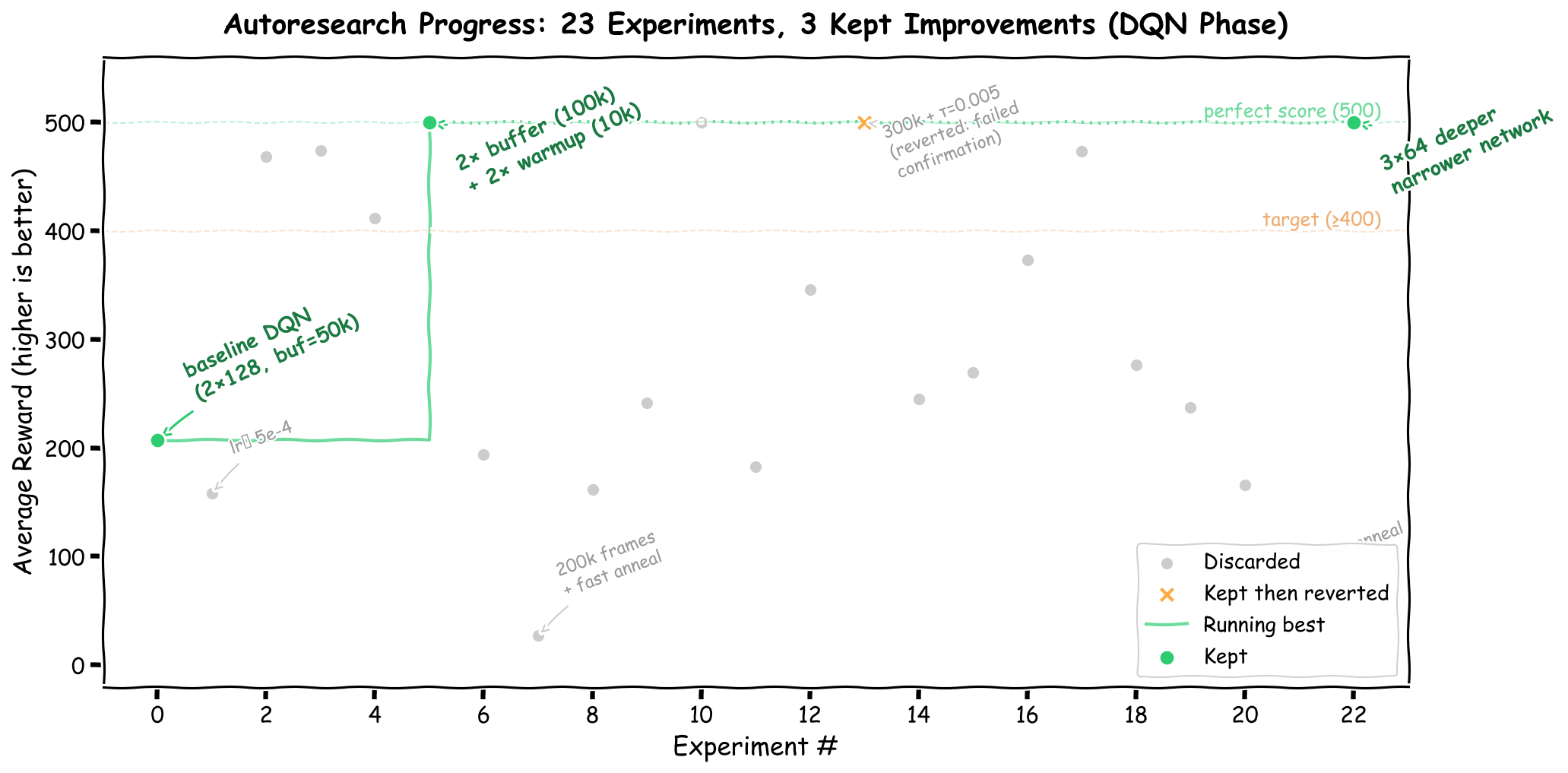
23 experiments on DQN hyperparameters. Green circles mark kept improvements; gray dots are discards. The staircase tracks the running best metric.
| Iteration | Change | METRIC | Status |
|---|---|---|---|
| 0 | Baseline DQN | 207.6 | baseline |
| 1 | lr | 158.4 | discard |
| 5 | Buffer , warmup | 500.0 | keep |
| 13 | Total frames , | 500.0 245.2 | discard (failed confirmation) |
| 22 | Network | 500.0 | keep |
The breakthrough came at iteration 5: doubling the replay buffer (to 100k) and the warmup period (to 10k frames) stabilized learning dramatically. The larger buffer provides more diverse training data, and the longer warmup ensures the buffer contains enough varied transitions before gradient updates begin. This single change took the agent from an unstable 207.6 to a confirmed perfect 500.
A deeper, narrower network ( instead of ) was kept at iteration 22 as well --- it produced a more stable representation that jumped directly from the “stuck at 9” phase to 500 without the intermediate oscillation.
But the best DQN configuration still required 421,000 frames and about 3 minutes of wall-clock time. Could we do better?
Phase 2: The Algorithm Switch (Iterations 23--39)¶
At iteration 23, we expanded the search space beyond DQN to include other RL algorithms. Four candidates were tested in parallel:
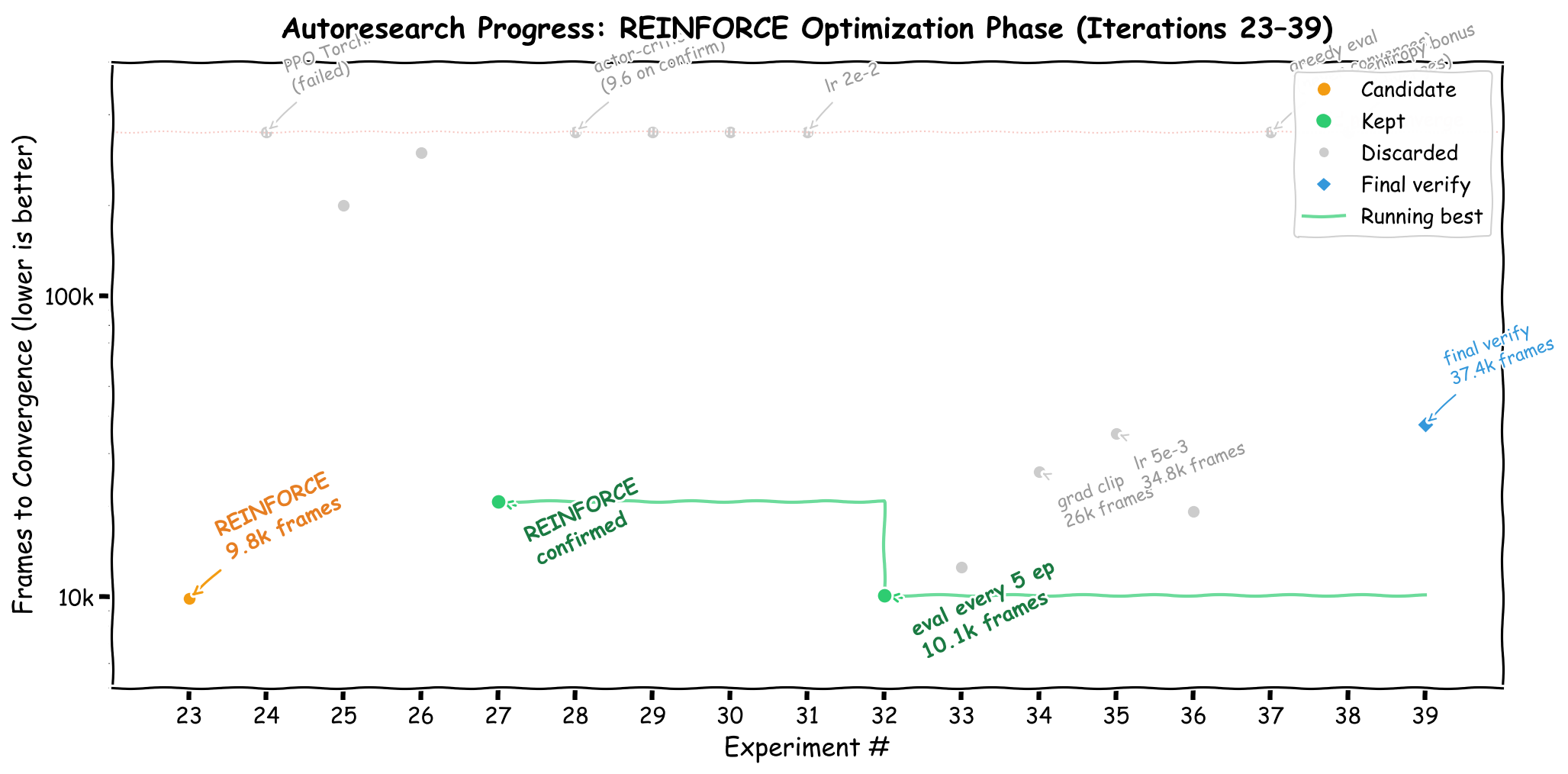
17 experiments optimizing REINFORCE. The y-axis (log scale) shows frames to convergence --- lower is better. Experiments that never converged float near the top.
| Algorithm | METRIC | Frames | Time |
|---|---|---|---|
| REINFORCE | 497.8 | 9,868 | 4.8s |
| PPO (TorchRL) | 8.8 | 100,352 | 46.8s |
| DQN (aggressive) | 273.0 | 200,000 | 65.2s |
| Double DQN | 236.0 | 300,000 | 91.9s |
REINFORCE --- the simplest policy gradient algorithm, dating back to Williams (1992) [Williams, 1992] --- crushed DQN by achieving near-perfect reward in 43 fewer frames. The entire implementation is under 80 lines of pure PyTorch:
policy = nn.Sequential(nn.Linear(4, 128), nn.ReLU(), nn.Linear(128, 2))
optimizer = torch.optim.Adam(policy.parameters(), lr=1e-2)
# For each episode: collect trajectory, compute returns,
# update policy with REINFORCE gradient
loss = -sum(log_prob * G for log_prob, G in zip(log_probs, returns))No replay buffer. No target network. No -greedy exploration. No TorchRL dependency. Just a two-layer network, Adam at , and the vanilla policy gradient theorem.
The remaining iterations (28--39) attempted to improve the REINFORCE implementation further: actor-critic baselines, entropy bonuses, gradient clipping, learning rate tuning, and deterministic evaluation. None of them improved on the base REINFORCE. Several actively hurt performance:
Actor-critic (iteration 28): scored 500 in a parallel test but collapsed to 9.6 on confirmation --- a cautionary tale about trusting unconfirmed parallel results
Entropy bonus (iteration 38): prevented convergence entirely (METRIC = 114.8) by encouraging too much exploration
Gradient clipping (iteration 34): smoothed the training curve but slowed convergence from 10k to 26k frames
The only improvement that stuck was evaluating every 5 episodes instead of 10 (iteration 32), which caught convergence earlier without affecting training dynamics.
What We Learned¶
1. Simpler algorithms win on simple problems¶
CartPole has a 4-dimensional observation space and 2 actions. DQN’s machinery --- replay buffers, target networks, -greedy schedules --- is designed for complex, high-dimensional environments like Atari [Mnih et al., 2015]. For CartPole, this machinery is pure overhead. REINFORCE’s direct policy gradient is sufficient and dramatically more efficient.
This is not a novel insight (any RL textbook will tell you this), but the autoresearch loop rediscovered it empirically in 39 iterations without being told which algorithm to prefer.
2. Parallel experiments need confirmation runs¶
We ran batches of 4 experiments in parallel using Python’s ProcessPoolExecutor. This was excellent for screening --- it identified REINFORCE as a candidate in one batch --- but parallel results cannot be trusted as final. Process-level non-determinism (even with fixed seeds) means that a metric achieved in a forked subprocess may not reproduce when running the same script directly. Three experiments that scored 500 in parallel failed their confirmation runs.
The protocol that worked: use parallel batches for exploration, then always verify winners with a sequential confirmation run before committing.
3. RL metrics are inherently noisy¶
Across our 39 iterations, the same configuration could produce METRIC values ranging from 484 to 500 on different runs. REINFORCE is especially volatile: the agent might solve CartPole at episode 80 (10k frames) on one run and episode 235 (37k frames) on the next.
This noise makes the autoresearch keep/discard decision harder than in deterministic domains like test coverage or bundle size. We found that seed pinning helps with the training side (torch.manual_seed(0), env.reset(seed=episode)), but evaluation remains stochastic. The best strategy is to accept the variance and focus on whether changes produce consistently good results across multiple runs, rather than chasing a single peak metric.
4. Git as memory is powerful¶
The autoresearch loop’s use of git as memory proved invaluable. Every experiment --- successful or not --- lives in the commit history. The agent can read git log to see what was tried, inspect git diff on kept commits to understand why something worked, and avoid repeating failed approaches. Over 39 iterations, this produced a rich experimental record that a human researcher could review in minutes.
Final Numbers¶
| Configuration | Commit | METRIC | Frames | Wall Time |
|---|---|---|---|---|
| DQN Baseline | 2cb5664 | 207.6 | ~421,000 | ~3 min |
| DQN Optimized (buffer + warmup + 364 net) | 6c821f9 | 500.0 | ~421,000 | ~3 min |
| REINFORCE (eval every 5 episodes) | a066fb7 | 500.0 | ~10,000 | ~5 sec |
39 iterations. 4 keeps. 34 discards. 0 crashes. One algorithm switch that changed everything.
Conclusion¶
The autoresearch loop proved remarkably effective on CartPole-v1: 39 automated iterations rediscovered a textbook result --- that simple policy gradients outperform DQN on low-dimensional problems --- without any human guidance on algorithm selection. The agent explored, failed, backtracked, and ultimately converged on an 80-line REINFORCE implementation that solves the task in under 10 seconds.
But CartPole is the simplest RL toy problem there is, the far more compelling question is whether this pattern scales. What happens when you point the autoresearch loop at sophisticated environments? These high-dimensional settings are where the real algorithmic design challenges live --- and where the search space of possible modifications explodes.
The fundamental bottleneck is compute. Each CartPole experiment ran in seconds; a single Atari training run can take hours on a GPU. Exhaustive hyperparameter sweeps across RL algorithms and environments are already prohibitively expensive --- the HPO-RL-Bench project [Shala et al., 2024] required pre-computing reward curves for six algorithms across 22 environments just to make hyperparameter research tractable without re-running training. An autoresearch loop that iterates hundreds of times on environments of that scale would demand cluster-level resources.
This is where understanding scaling laws becomes critical. Recent work has shown that value-based deep RL follows predictable scaling behavior with respect to model size, replay ratio, and compute budget --- provided hyperparameters are set carefully [Rybkin et al., 2025]. If similar predictability holds for the autoresearch pattern, one could screen algorithmic modifications cheaply on small-scale proxies and transfer the winners to full-scale training. Even without having Karpathy’s or frontier labs resources available. Characterizing when and why small-scale RL improvements transfer --- and when they do not --- would transform autoresearch from a curiosity on toy problems into a practical tool for RL algorithm development at scale.
Citation¶
The full experiment log, git history, and code are available in the autoresearch-dqn repository.
@misc{schwinger2026autoresearch-dqn,
title = {Autoresearch {RL} algorithms to solve Cartpole},
author = {Raphael Schwinger},
year = {2026},
howpublished = {Blog post},
url = {https://schwinger.dev/autoresearch-dqn},
}- Karpathy, A. (2026). autoresearch: AI agents running research on single-GPU nanochat training automatically. https://github.com/karpathy/autoresearch
- Goenka, U. (2026). Claude Autoresearch Skill — Autonomous goal-directed iteration for Claude Code. https://github.com/uditgoenka/autoresearch
- Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., & Riedmiller, M. (2013). Playing Atari with Deep Reinforcement Learning. arXiv Preprint arXiv:1312.5602.
- Williams, R. J. (1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 8(3–4), 229–256. 10.1007/BF00992696
- Bou, A., Bettini, M., Dittert, S., Kumar, V., Sodhani, S., Yang, X., De Fabritiis, G., & Moens, V. (2024). TorchRL: A data-driven decision-making library for PyTorch. arXiv Preprint arXiv:2306.00577.
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., & others. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529–533. 10.1038/nature14236
- Shala, G., Arango, S. P., Biedenkapp, A., Hutter, F., & Grabocka, J. (2024). HPO-RL-Bench: A Zero-Cost Benchmark for HPO in Reinforcement Learning. Proceedings of the Third International Conference on Automated Machine Learning, 256, 18/1-31. https://proceedings.mlr.press/v256/shala24a.html
- Rybkin, O., Nauman, M., Fu, P., Snell, C., Abbeel, P., Levine, S., & Kumar, A. (2025). Value-Based Deep RL Scales Predictably. Proceedings of the International Conference on Machine Learning (ICML).